


智源 Emu3 生成的 AI 视频案例
全球首个原生多模态寰球模子来了。
钛媒体 App 获悉,10 月 21 日,北京 AI 领域新式非谋利盘问机构北京智源东谈主工智能盘问院(以下简称"智源盘问院",BAAI)发布接受了自转头(autoregressive)技能道路的原生多模态寰球模子 Emu3,并同步上线技能文档、开源要津技能等供产业界进一步探索。
据悉,Emu3 参数目为 8B(80 亿),只基于下一个 token(输入数据的基本单元)估计,无需扩散模子或组合式方法,把图像、文本和视频编码为一个闹翻空间,在多模态夹杂序列上重新启动聚合检修一个 Transformer 模子。该模子完了了视频、图像、文本三种模态的融合清爽与生成,传统模子则只可处理一种类型。而在图像生成、视觉言语清爽、视频生成任务中,Emu3 的发扬跳动了图像生成模子 Stable Diffusion SDXL 、视觉言语清爽模子 LLaVA、视频生成模子 OpenSora 等国表里主流开源模子,展示了海外当先的 AI 技能。
智源盘问院院长王仲远向钛媒体 App 等示意,Emu3 讲明了下一个 token 估计能在多模态任务中有高性能的发扬,这为构建多模态 AGI 提供了广袤的技能出路。Emu3 有契机将基础设施竖立不竭到一条技能道路上,为大领域的多模态检修和推理提供基础,这一通俗的架构假想将利于产业化。改日,多模态寰球模子将促进机器东谈主大脑、自动驾驶、多模态对话和推理等场景应用。
王仲远强调,行业一定会有一个融合的多模态模子。
"智源会坚执作念原始窜改。咱们觉得原生大一统的多模态大模子,是所有大模子发展技能道路上必须要去攻克的一个技能标的。Emu3 是全球首个基于该技能道路的原生多模态寰球模子,并面向海外社区进行了开源。"王仲远坦言,中国在大模子的技能道路上要有我方的中枢技能,而 Emu3 能为多模态大模子检修范式指明新的标的。
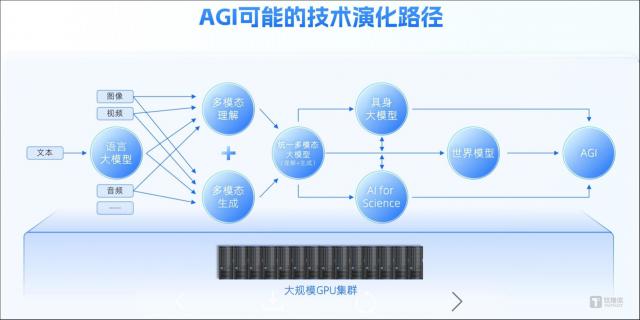
图像文本视频大一统,王仲远:原生多模态寰球模子处在" GPT-3 时刻"
智源盘问院成立于 2018 年 11 月,是全球最早开展 AI 大模子的中国非谋利性新式盘问机构,亦然北京市继脑科学与类脑盘问中心、量子信息科学盘问院之后,效用竖立的又一个迫切的新式研发机构。
智源盘问院为了加速 AI 前沿技能落地,围绕大模子、类脑脉冲芯片、理解学问图谱、安全东谈主工智能、疾病脑电、智能信息处理等当先技能的纯熟化、工程化成就窜改中心,推动 AI 原创后果弯曲及产业化。
2024 年 2 月,智源盘问院告示王仲远博士担任新任院长,全面崇拜盘问院各项责任。在此之前,王仲远在 AI 学术及产业领域深耕长达 15 年以上,曾在微软、Facebook(现 Meta)、好意思团、快手等多家头部公司任职过。
Emu3 所使用的自转头技能道路的中枢想想是应用序列数据中的高下文依赖性来估计改日的数据点。该类型模子中,不同模态数据分享归拢套参数,可完了跨模态的关联和生成,无需东谈主工假想的特征工程。同期因自转头技能道路的特色,在生成数据时模子必须按步履进行,为止了并行计较的才智,导致生成速率较慢。也会碰到耐久依赖问题,即模子难以捕捉序列中较远距离的依赖关系。
所谓"寰球模子"是面前技能派别中难度最高的一种,其特色在于让机器冒昧像东谈主类通常对着实寰球有一个全面而准确的理解,不仅包括对事物的样貌和分类,还包括对事物的关系、规则、原因和扫尾的清爽和估计,从而进行推理和决策,而"寰球模子"也被觉得是通往 AGI 的最优解。
同期,谷歌与麻省理工学院(MIT)何恺明团队聚合鼓励了一个新盘问表情,推出名为 Fluid 的图像自转头模子,接受连结 token 生成形势和当场步履生成单张图片;图灵奖得主、Meta 首席 AI 科学家杨立昆(Yann LeCun)指引的 Meta AI 团队曾推出 V-JEPA 寰球模子,一种通过不雅看视频来教机器清爽和模拟物理寰球的方法;李飞飞提到的所谓"空间智能"亦然寰球模子的一种技能标的;而在国内,智源盘问院也率先推出自转头道路多模态寰球模子 Emu3。
王仲远觉得,Emu3 的发布意味着大模子冒昧通过更多维度的数据来清爽、学习着实寰球。
具体来看,把柄智源盘问院 9 月底发布的技能理解,Emu3 模子参数目为 80 亿,包括了笔墨、图片和视频原始数据,并将视觉数据 Token 化从而在融合的架构下进行检修,不错生成笔墨、各样化作风的图片和最长为 5 秒的视频,而且能执续估计下一个 Token 词元。
评测扫尾闪现,英文提醒词下,该模子图片生成得分为 70.0 分,当先于 Stability AI 于 2023 年 7 月推出的 SDXL 的 66.9,逾期于 OpenAI 于 2023 年 8 月推出的 DALL E3 的 73.4 分;文生视频得分则为 81.0 分,当先于本年 6 月开源的 OpenSora 1.2 的 79.6 分;言语才智,技能理解未提供联系测评数据,主要由于 Emu3 言语类数据占比小,参数远小于市面上其他的言语大模子,因此眼引子语才智并不在第一梯队,但 Emu3 模子词汇量达 184622,高下文长度达到 131072,具有好多言语模子的技能才智。
王仲远觉得,面前接受自转头架构构建融合的多模态寰球模子仍处在应用爆发前的" GPT-3 时刻",如今的多模态领域还处于荒谬早期,因此 Emu3 只是在前沿技能层面讲明了该道路的可能性,改日仍需和产业界协调进一步扩大检修领域,并将 Emu3 推向大家冒昧涉及的应用。
算力、数据、生态仍是面前多模态寰球模子的挑战
事实上,近期对于" OpenAI 研发的 AI 模子技能是否是改日通用东谈主工智能(AGI)的标的"争议颇多。其中,苹果公司里面职工承认"生成式 AI 技能逾期竞品两年以上",外部径直质疑 OpenAI o1 的 AI 推理才智较差,无法处置部分小学数学题内容;而杨立昆则直言,今天的 AI 大模子比猫还笨,致使觉得 Sora 并不成的确清爽物理寰球,这么的视频生成与寰球模子的因果估计仍然存在纷乱各异。
对此,王仲远向钛媒体 App 坦言,他部分认同杨立昆的说法,确乎需要多模态寰球模子通往 AGI 办法,但不一定要鉴戒生物大脑假想多个不错类比的自主性 AI 系统子功能模块这种决策。
"杨立昆提的对于面前大模子比猫还笨,很迫切的一个论点是他觉得纯言语模子无法抵达 AGI。咱们也觉得纯言语模子是不够的,因为仅从文本层面无法统统帅略寰球。事实上,一些科学家,包括谢赛宁博士,在尝试通过视觉信号直战争发智能才智的技能道路。言语是迫切的,但独一言语是不够的。要是要清爽感知、推理这个寰球,起初要看得回、嗅觉到寰球,才能把不同模态的信息进行交互清爽。这恰正是 Emu3 融合多模态技能道路的迫切孝敬。但另一方面,对于杨立昆提议来仿照东谈主脑假想自主 AI 系统模块,我觉得应该耐久饱读动和撑执不同的技能道路的探索,融合多模态寰球模子便是其一。"王仲远示意。
Keras 之父 Francois Chollet 也觉得,大模子通过提醒使用时,无法清爽与检修数据中情况大相径庭的情况,因此不具备通用智能,而大模子的主要作用是手脚实质 AGI 的学问和法子存储,它们是一种挂牵形式,而智能不单是是挂牵。
不外,面前 Emu3 这种原生多模态寰球模子依然存在诸多"局限性",比如所有检修数据领域不够大,低于 Emu2 的 370 亿参数和东谈主类的 860 万亿 -1000 万亿神经元领域,使得言语效果无法达到 GPT-o1 水平;算力领域不够大,面前智源的 AI 异构算力平台与行业最大领域的算力集群领域依然有一定距离;另外,面前寰球模子道路莫得生态和本质者,亟待更多企业和大公司进行生意落地,从而考据这条道路的正确性。
"咱们需要更多资源,举例,Emu3 参数扩大 10 倍所需的算力、工程化的才智是指数级增多的,是以需要协调伙伴和咱们沿途检修下一代的模子。"王仲远对钛媒体 App 示意。
谈及预检修大模子不再检修时,王仲远强调,在技能道路不竭的趋势下,厂商会更积极地探索模子的落地场景。从乐不雅的角度来看,阐发基础大模子还是达到一定的才智水平。另从严慎的角度来说,检修转推理阐发仅靠阛阓驱动,会令厂商堕入"跟从者"的境地,不利于原始技能窜改。
"咱们一直强调智源的定位,是作念原始窜改,作念企业不肯意作念,高校作念不了的事情,是以这使得咱们必须作念下一代 AI 技能探索,作念改日 3 年 -5 年可能被行业招供的技能道路。在多模态方进取,智源需要为所有行业指明一个标的。"王仲远称。
以下是智源盘问院团队与钛媒体 App 等部分对话疏导整理:
问:比较 Emu 2,Emu3 模子参数目减少,幻觉会不会更严重?
智源盘问院:起初通俗先容 Emu3 和 Emu 2 的技能离别。Emu2 视觉用的照旧 embedding 的形势,Emu3 造成了闹翻的 token。Emu1,Emu 2 是宗旨考据加探索迭代。其时用了预训好的言语模子和扩散的 decoder,快速考据融合的生成式是否能走通,智源是海外上最早作念的探索。因为不需要检修言语模子,基于已有的,本钱会比较低。Emu3 咱们是统统重新检修,是为视频图像文本原生多模态假想的。
问:Emu3 视频好像最多 5 秒 24 的 FPS,这与其他估计模子的离别?
智源盘问院:下一个 token 自然的平正是自己就不错续写,看到前边的 token 估计后头的 token,不错无穷续下去。只是要是在一个场景续写,看到的长视频齐是一个场景,预见不大。面前举座的续写才智还莫得冲突长的多情节的视频生成。Emu3 这套框架的特有上风便是因果性,不错基于前边发生的事情估计后头发生的事情,而不是基于一堆噪声去想象。Emu3 面前不错 5 秒一直续写。
问:有莫得贪图在科学计较上的应用?
智源盘问院:AI for Science 多模态诅咒常必须的。GPT 3 到 ChatGPT 花了两年半的时刻,Emu3 好比曩昔的 GPT3,Emu3 是一个中间的 milestone(里程碑),下一个期待雷同 ChatGPT 的的 milestone。
问:智源改日三到五年之内的重心是什么?
智源盘问院:连续研发原生多模态寰球模子 Emu 系列,处置更大领域的数据、算力以及检修 。融合多模态基座大模子是东谈主工智能参加到物理寰球荒谬迫切的基座。多模态具身大脑亦然盘问院正在作念的盘问。本年咱们也看到了诺贝尔的物理学奖给了 Hinton 阐发注解,化学奖是给了 DeepMind 团队。AI for Science 亦然智源荒谬关怀的迫切盘问标的。
问:从 To C 端角度来说,APP 细目是最佳的形势,智源改日有莫得贪图和一些其他协调伙伴推出一些 c 端 APP?
智源盘问院:面前阛阓上的言语模子 APP 还是启动基于百亿模子在使用,这个前提是有了千亿、万亿模子,达到更高的性能,百亿模子效果随之更好。而面前,多模态大模子还在无间探索才智上限。智源探索出了 Emu3 这么一条技能道路,那么接下来需要展示,也期待在多模态领域的" ChatGPT " 的时刻。
我想再一次强调 Emu3 架构的优厚性,将来多模态大模子齐冒昧荒谬容易使用,这是 Emu3 模子的预见。
(本文首发于钛媒体 App,作家|林志佳,裁剪|胡润峰)